

Announcing Chapel 2.7!
Highlights from the December 2025 release of Chapel 2.7
writeln("Hello, world!");
// create a parallel task per processor core
coforall tid in 0..<here.maxTaskPar do
writeln("Hello from task ", tid);
// print these 1,000 messages in parallel using all cores
forall i in 1..1000 do
writeln("Hello from iteration ", i);
// print a message per compute node
coforall loc in Locales do
on loc do
writeln("Hello from locale ", loc.id);
// print a message per core per compute node
coforall loc in Locales do
on loc do
coforall tid in 0..<here.maxTaskPar do
writeln("Hello from task ", tid, " on locale ", loc.id);
// print 1,000 messages in parallel using all nodes and cores
use BlockDist;
const Inds = blockDist.createDomain(1..1000);
forall i in Inds do
writeln("Hello from iteration ", i, " running on locale ", here.id);
use IO;
// read in a file containing 'city name;temperature' lines (1BRC-style)
const stats = [line in stdin.lines()] new cityTemperature(line);
writeln(stats);
record cityTemperature {
const city: string; // city name
const temp: real; // temperature
proc init(str: string) {
const words = str.split(";");
this.city = words[0];
this.temp = words[1]: real;
}
}
// set different values at runtime with command line arguments
// e.g. --n=2048 --numSteps=256 --alpha=0.8
config const n = 1000,
numSteps = 100,
alpha = 1.0;
const fullDomain = {1..n},
interior = {2..n-1};
var u: [fullDomain] real = 1.0;
u[n/4..3*n/4] = 2.0; // make the middle a bit hotter
var un = u;
for 1..numSteps {
forall i in interior do // shared-memory parallelism
u[i] = un[i] + alpha * (un[i-1] - 2*un[i] + un[i+1]);
un <=> u; // swap the two arrays
}
writeln(un);
use Random, Math;
const nGpus = here.gpus.size,
n = Locales.size*nGpus;
var A: [1..n, 1..n] real;
fillRandom(A);
// use all nodes
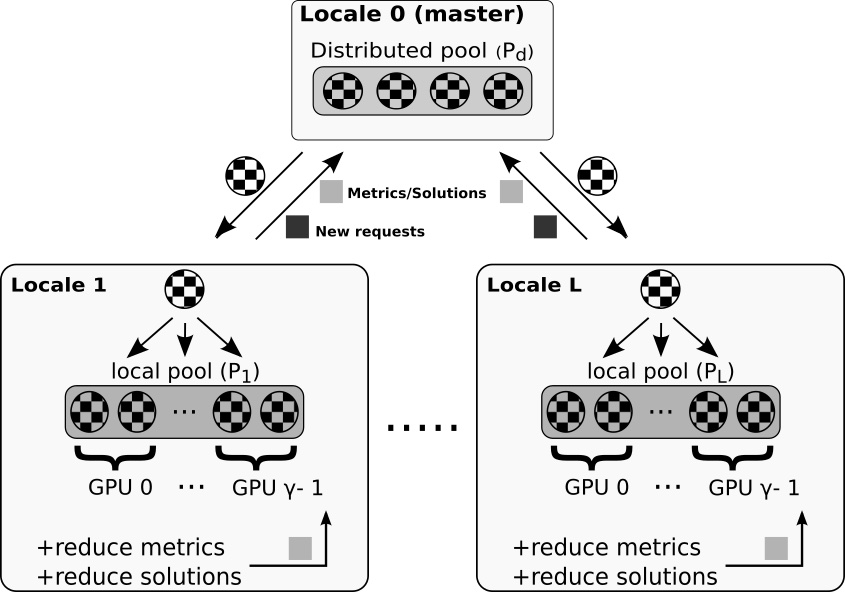
coforall (loc, localRowStart) in zip(Locales, 1.. by nGpus) do on loc {
// and all GPUs within each
coforall (gpu, row) in zip(here.gpus, localRowStart..) do on gpu {
var B: [1..n] real = A[row, ..]; // copy a row from device to host
B = asin(B); // compute (kernel launch)
A[row, ..] = B; // copy the row back
}
}
writeln(A);
Written by students and post-docs in Eric Laurendeau's lab at Polytechnique Montreal. Outperformed its C/OpenMP predecessor using far fewer lines of code. Dramatically accelerated the progress of grad students while also supporting contributions from undergrads for the first time.

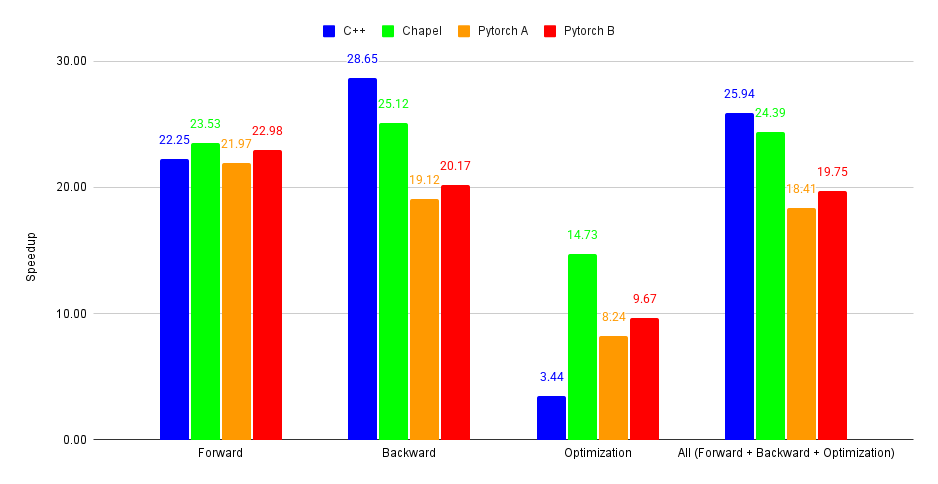
Comparison of transformers in Chapel, C++, and PyTorch focusing on multi-threaded CPUs

A retrospective on ChapelCon ‘25 from general chair Brandon Neth

Chapel is now an official project of the High Performance Software Foundation / Linux Foundation
A new quarterly newsletter is now available, covering SC25 events, updates from various talks, and more
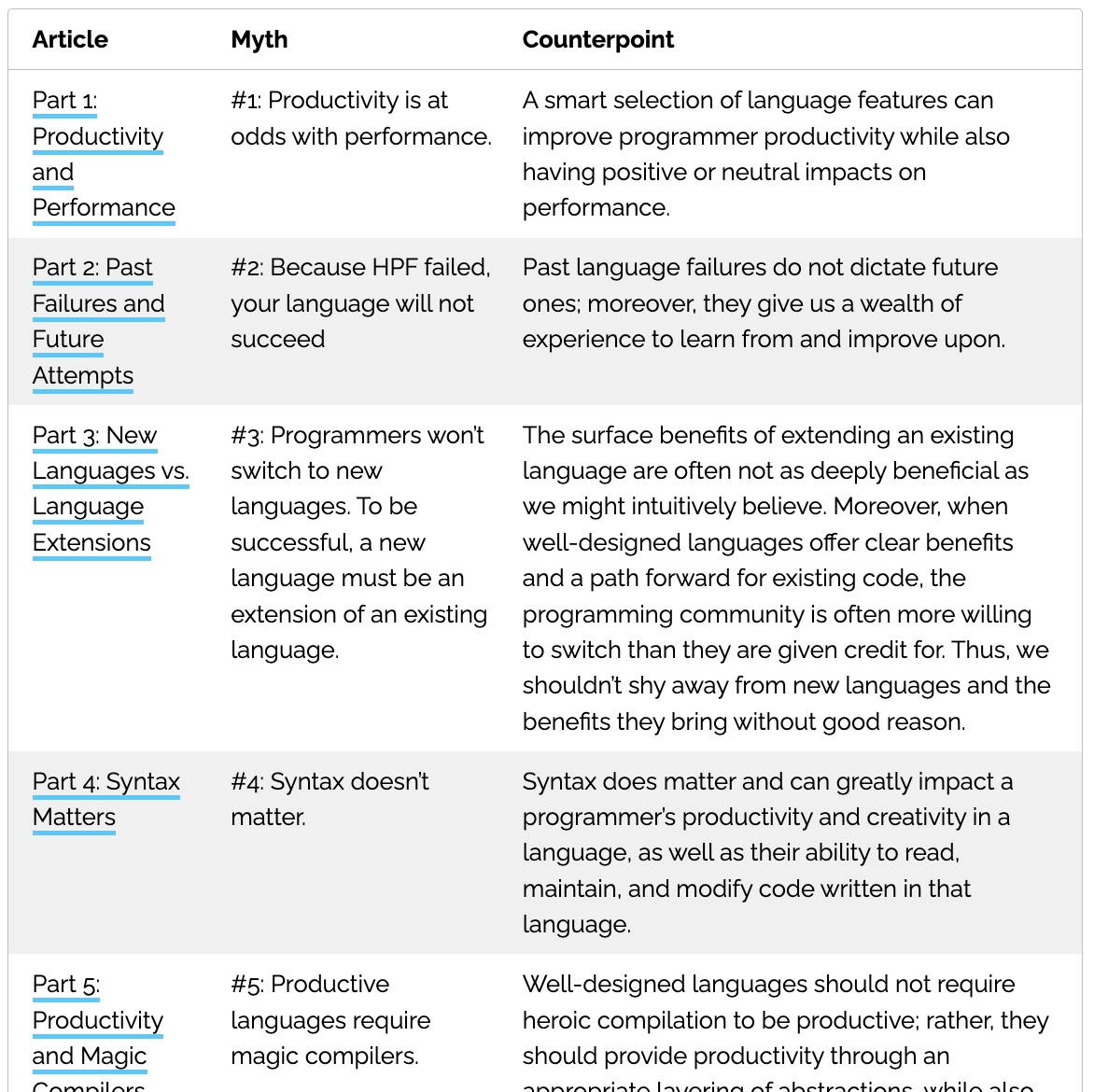
The eighth and final archival post from the 2012 IEEE TCSC blog series, with a current reflection on it